虽然 Control Net 还不能原生支持多种 input condition, 但加上人工的后期处理,我们可以看见其应用潜力。 使用两种引导条件分别生成人物和场景
人物使用 post skeleton 引导,场景使用 depth map 引导。分别生成完再进行合成。分开引导效果更好,也让创作设计更为灵活。(人物合成前需要抠图。另外别忘了给人物添加投影)
结合 Blender 使用 ContrelNet 创作 3D
Blender 里面创建的 3D 模型,导出静态图片作为 input image,使用 controlnet 的深度检测生产图像,再作为贴图贴回 blender 里的原模型上,bingo!虽然用于人体这类复杂曲面,效果会比较粗糙,但用于包装盒或建筑这类简单的几何体,应该会非常实用。
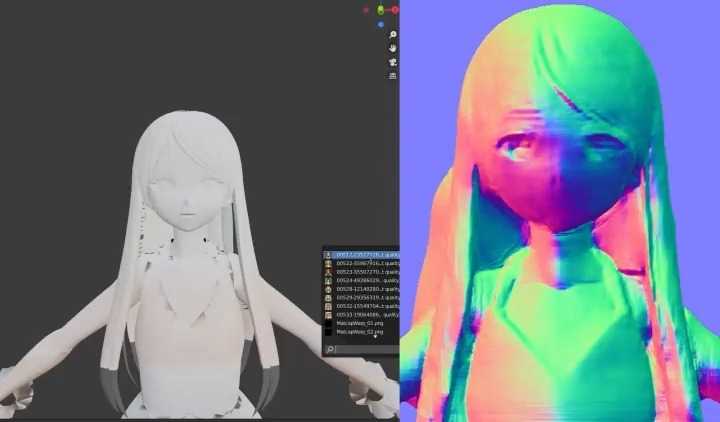
https://twitter.com/TDS_95514874/status/1626331836459671552?s=20twitter.com/TDS_95514874/status/1626331836459671552?s=20Use Controlnet's Normal mode to convert the 3D model into an illustration or anime style, then paste it as a texture on the original 3D model.
Normal mode reflects the detailed structure well, so you can texturing quite accurately. 结合 Blender 使用 ContrelNet 创作动画
在 Blender 里生成3D模型后,用不同颜色标记各个部位,再把动画序列导出后 在 ControlNet 里作为 Segmentation map condition 输入,生成的动画,各部件的结构有更好的稳定性和一致性,特别适用于身体部件之间有遮挡的动作。
https://twitter.com/TDS_95514874/status/1626817468839911426?s=20
Rendering by color-coding materials for each part → If you use i2i with Segmentation of controlnet, the accuracy will increase considerably.
I think that it is effective especially in the part where the parts intersect and the subtle angle of the face. 使用两种输入引导的组合创作动画
人物动作使用 post skeleton 引导,场景使用 depth map 引导。分别生成完再进行合成。虽然还不是真正的 text to animation 生成,但这种方法已经能获得比之前都好的效果,更少的 glitch interference (跳帧感),人物动作更流程,背景也更稳定。