ioty LV
发表于 2025-4-27 17:59:56
对普通用户来说没啥影响,因为我们用的是 APP 或者是网页,没有使用API。
与其说AP I优惠到期,我更关心的是APP或者网页版本的使用,是否收费。
即使收费,我觉得性价比也远超 Chat GPT4 一万倍,你说呢?
不过到目前为止,也没有相关收费的信息。
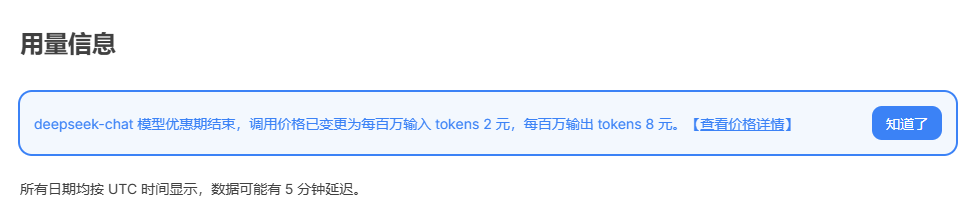
优惠到期,也就意味着恢复原价,或者说推广期结束,不过暂时还不能看到有什么影响,因为官网上还不能充值呢。
并且「去充值」按钮也是灰色的还不能使用。
按照正常的思维,在服务区资源缓解后,应该还会推出优惠。
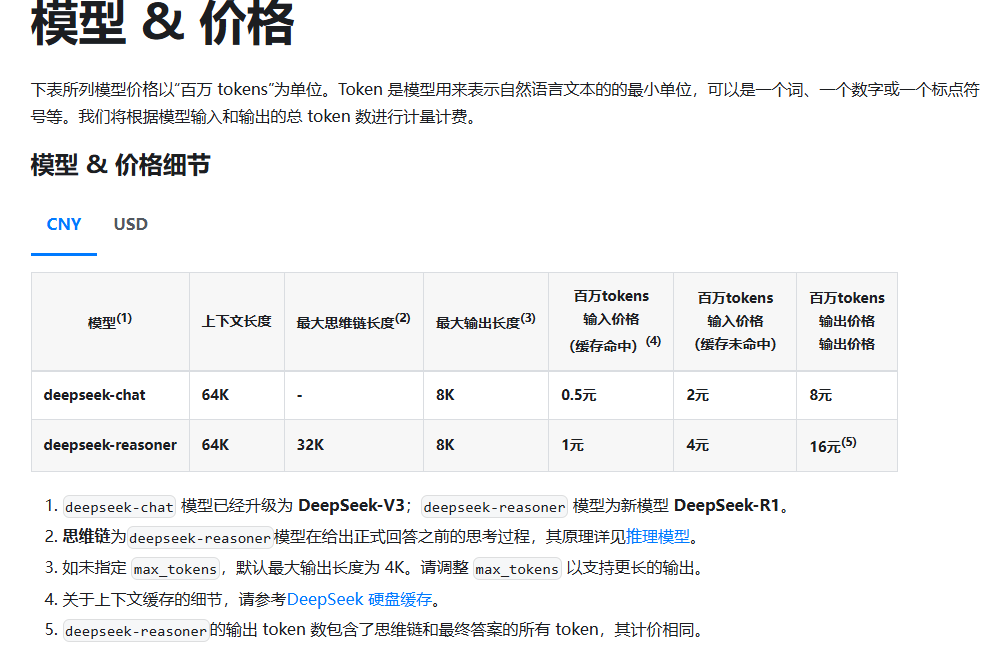
此外这个DeepSeek 恢复 V3 模型 API 价格,面对的是API接入用户收费的价格。
说实话这个价格相对还是很优惠的
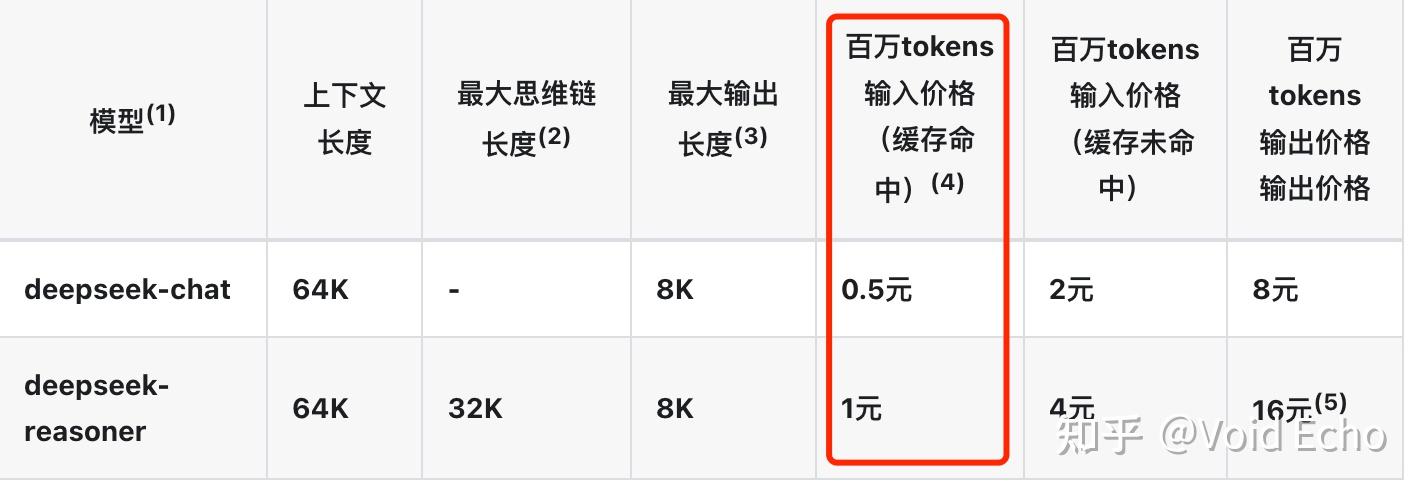
我们看一下 token的计算方法

1 个中文字符 ≈ 0.6 个 token,如果一次对话产生1000个汉字,那就是600个takens,按照百万tokens 16(因为我会启动 DeepSeek R1)元计算的话,600个tokens大约是 1分钱。
一个问题可能需要几次对话,这样的话一次交流需要几分钱。还是能接受的。
这几天由于「服务器忙」的原因,我也在用API,看我在昨天在「硅基流动」上产生费用大约是1毛3分钱。
我才用的方式是:ChatBox + 「硅基流动的DeepSeek API」的方式, 一共问了3个问题,每个问题3轮对话,平均一个4分钱吧。
而且这个地方注册就送14元,这么看还是能用一段时间的。
DeepSeek 满血版的功能相比 ChatGPT4也是不相上下的
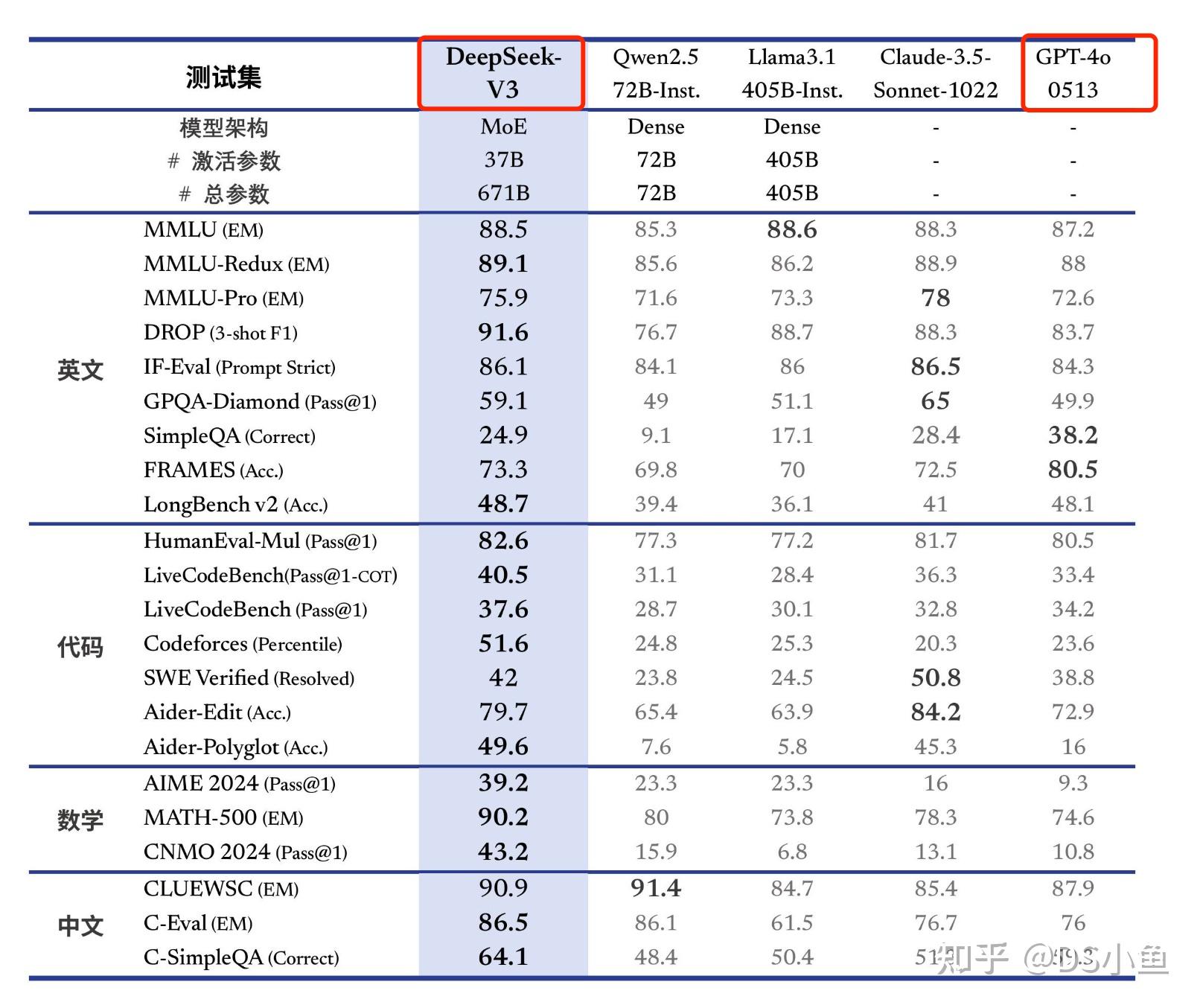
因此这个价格价值就是不要不要的,太亲民了。
|
|