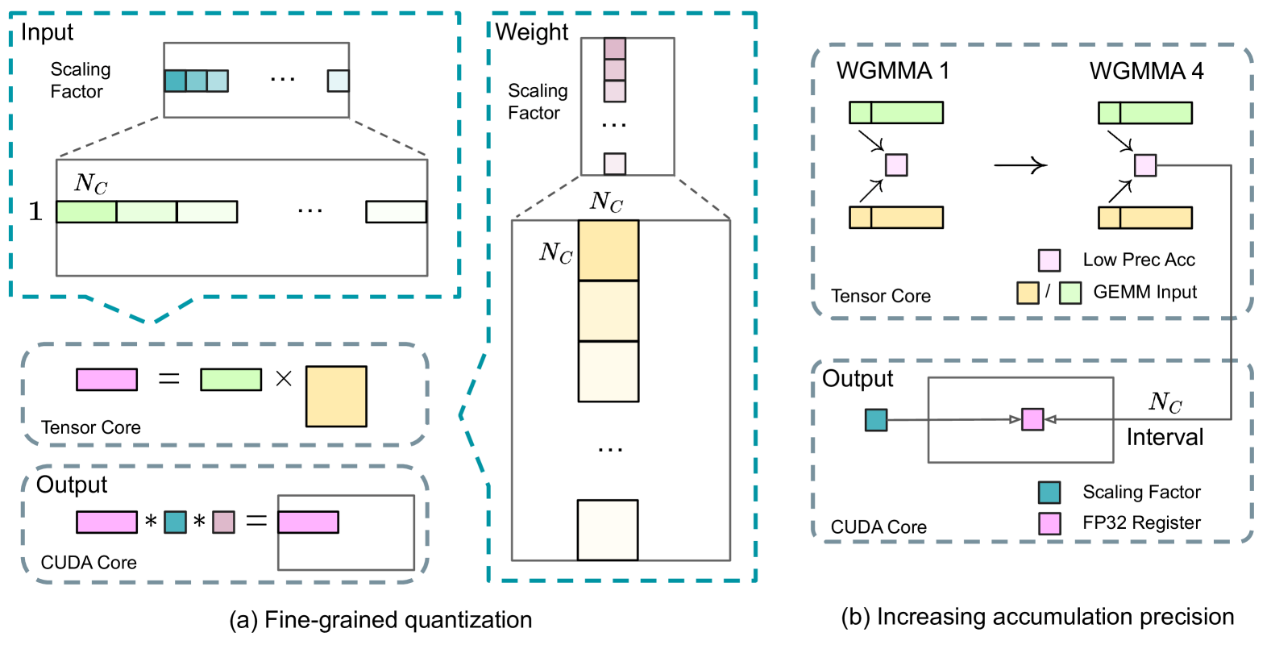
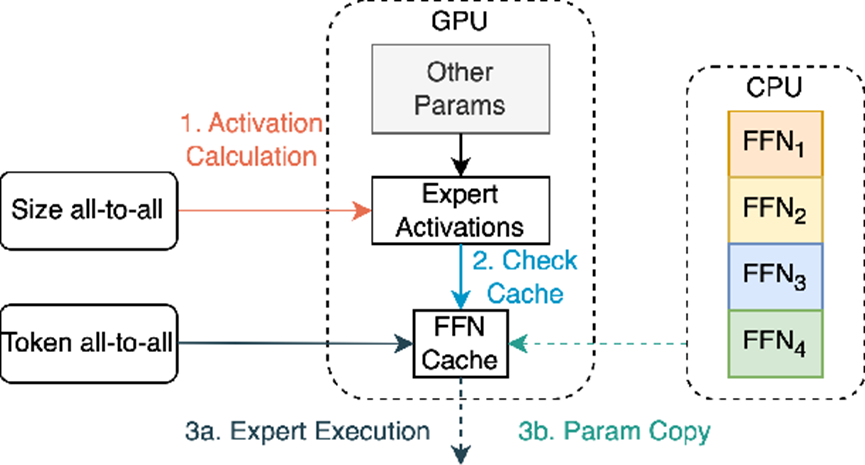
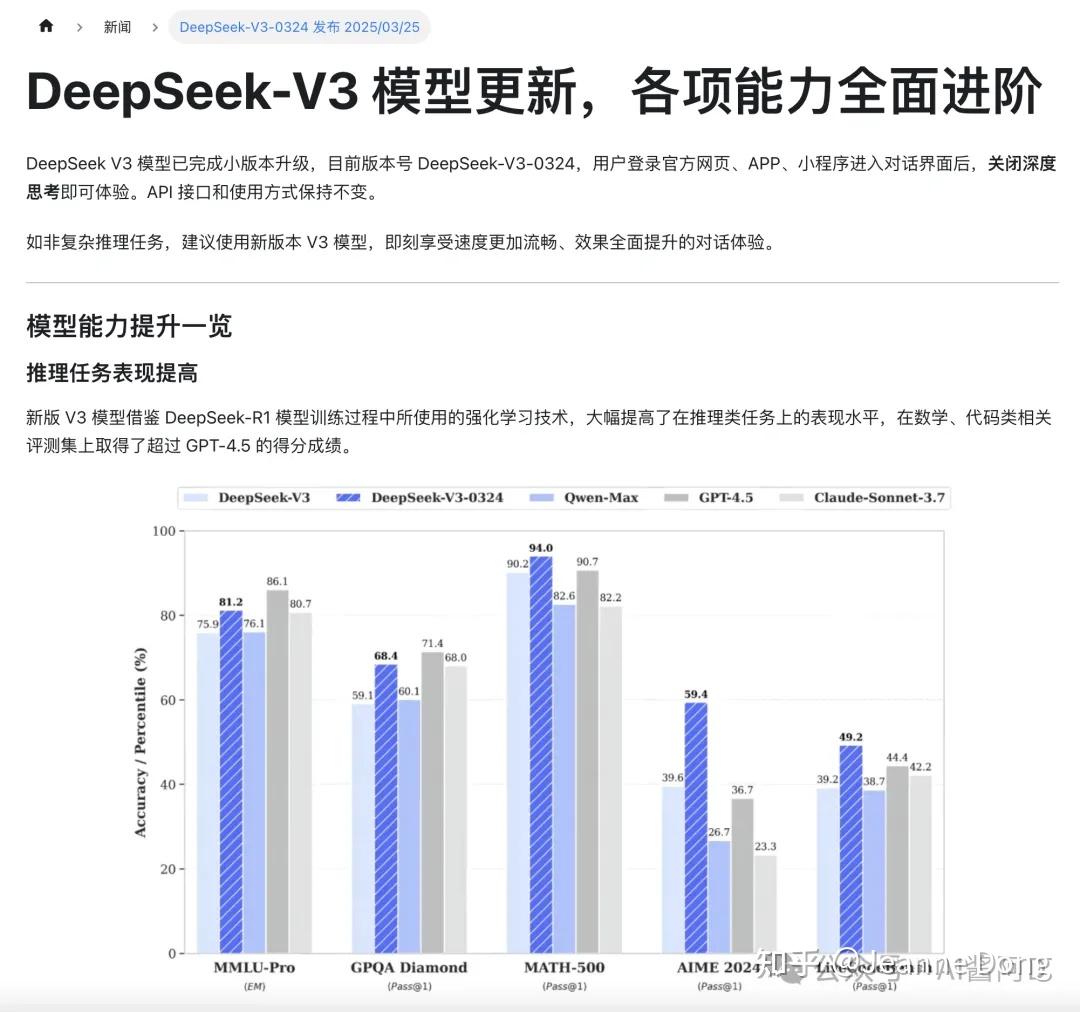
| 技术 | 方法说明 | 优势 |
| RMSNorm 和MLA Up-Projection 的重新计算 | 在反向传播期间重新计算所有MSNorm操作和MLA Up-Projection,无需持久存储其输出激活 | 以算代存,充分利用GPU内算力充沛但缓存不足的特点 |
| 在CPU内存中保存指数平均数指标(EMA) | 在CPU 内存中保存EMA,并在每个训练步骤后异步更新 | 把EMA从GPU显存占用改为CPU内存占用,释放动态存储空间 |
| 在多标记预测(MTP)中共享嵌入和输出头 | 使用DualPipe 策略,将模型最浅的层(包括嵌入层)和最深的层(包括输出头)部署在相同的PP等级上 | 允许MTP模块和主模型之间物理共享参数、梯度、嵌入和输出头,提升显存效率 |








 ,其中
,其中  表示token的数量,
表示token的数量,  表示专家集合,
表示专家集合,  表示第
表示第  个专家接受的token数量。如果是负载均衡的,那么每个专家收到的token一样多,token比例
个专家接受的token数量。如果是负载均衡的,那么每个专家收到的token一样多,token比例  所示。当所有专家收到token比例都相等时,
所示。当所有专家收到token比例都相等时,  取最小值。
取最小值。 
 是参数无关的量,不可梯度更新。可以用每个专家的门控权重的均值
是参数无关的量,不可梯度更新。可以用每个专家的门控权重的均值  作为
作为  的近似。如公式
的近似。如公式 

 为公式
为公式  计算的专家
计算的专家  为什么可以看作是
为什么可以看作是  。另外从定义上
。另外从定义上  表示token集合
表示token集合  其实是计算分配给专家
其实是计算分配给专家  也是计算分配给专家
也是计算分配给专家  的token数,是hard的计算。
的token数,是hard的计算。  和
和  的值是近似的(四舍五入取整的结果),也就是
的值是近似的(四舍五入取整的结果),也就是  ,所以
,所以 。
。
 计算引入了门控
计算引入了门控  项,
项,  ,保证了这个一个可微的计算,可以做梯度更新。
,保证了这个一个可微的计算,可以做梯度更新。 :
: 公式
公式