首页
发现AI主站
发现AI导航主站
Clawdbot中文版
Molili 一个真正做事情的AI Agents
登录/注册
注册
搜索
本版
帖子
用户
DeepSeek 升级 V3 模型,对比之前做出哪些改变?
【#DeepSeek升级V3模型#】DeepSeek25日对外宣布,DeepSeek V3模型已完成小版本升级,目前版本号 DeepSeek-V3-0324,用户登录官方网页、APP、小程序进入对话界面后,关闭深度思考即可体验。API接口和使用方式保持不变。据介绍,新版V3模型借鉴DeepSeek-R1模型训练过程中所使用的强化学习技术,大幅提高了在推理类任务上的表现水平,在数学、代码类相关评测集上取得了超过GPT-4.5的得分成绩。
收藏者
0
被浏览
614
【#DeepSeek升级V3模型#】DeepSeek25日对外宣布,DeepSeek V3模型已完成小版本升级,目前版本号 DeepSeek-V3-0324,用户登录官方网页、APP、小程序进入对话界面后,关闭深度思考即可体验。API接口和使用方式保持不变。据介绍,新版V3模型借鉴DeepSeek-R1模型训练过程中所使用的强化学习技术,大幅提高了在推理类任务上的表现水平,在数学、代码类相关评测集上取得了超过GPT-4.5的得分成绩。
2 个回答
agou
LV
发表于 2025-4-27 16:52:39
PS:看DeepSeek V3,强烈建议看完以下文章
Tang AI:DeepSeek系列:DeepSeek v1&MoETang AI:DeepSeek系列:DeepSeek-v2DeepSeek v3也是一个MoE的结构,比起DeepSeek V2其有3点的改进:
(1) 继续对MoE结构的负载均衡进行升级
(2) Multi-Token预测机制
(3) 对于COT-like的模型蒸馏
负载均衡的升级
Softmax to Sigmoid
对比DeepSeek V2的负载均衡loss,DeepSeek V3将gate网络的激活函数从softmax改为了sigmoid。
在DeepSeek V3中因为路由的专家增加到了近100个,当执行softmax操作的时候,如果专家数量过多会导致其数据的层次分明感不够。所选择的TopK个最大值可能区分度并没有那么大。而Sigmoid就不会像softmax那样受归一化的影响,区分度会更高一些。
辅助负载均衡loss
在DeepSeek v1和DeepSeek v2中还引入了专家级别loss、设备级别的loss和通信级别loss。在DeepSeek V3中它们都被移除了,引入了一个动态调整的bias作为替代
在这里
是gate网络的得分
是可训练的bias
在训练过程中,当我们检测到专家处于超载的状态,模型会减少
同样的,在宽松的情况下模型会增加
。
互补序列辅助损失
比起DeepSeek V1的专家级的平衡损失,互补序列辅助损失主要集中于计算一条样本下的token,而专家级的平衡损失注重于一个batch中而多个sequence的token。
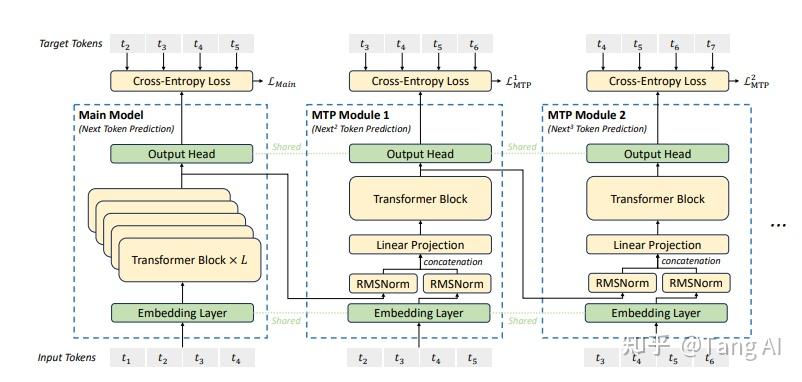
多Token预测(MTP)
MTP将对每个位置的单token预测,拓展到了对每个位置的多子序列token预测。具体的示意图如下图
DeepSeek V3 采用了D个序列MTP单元去预测D个子序列token。每个MTP单元包含一个共享的embedding层,一个输出head层,一个transformer块和一个线性映射层。
在这里
是在第k-1层的第i个token的输出表达
是第i+k个token的embedding
T是输入的序列长度
TRM是一个transformer块
OutHead主要是一个softmax+linear层
MTP的loss如下
在这里
T是输入的序列长度
是第i个token
是第k个MTP模块中
的预测概率
是权重系数
是MTP模块的数量
注意:MTP模块仅用于训练阶段,不用做推理。此外,还可以重新利用MTP去进行推测性解码(即一次预测多个后续token)从而减少生成的时延。
对于COT-like模型的知识蒸馏
SFT
在SFT阶段,DeepSeek V3增加了150万的多领域的instruction data。具体来说,它采用了DeepSeek R1的reasoning数据(该模型是DeepSeek V3的一个中间产物,会在下一篇文章进行介绍)。
然而,DeepSeek R1的输出相对较长,并且包含大量冗余信息。为了解决这个问题,对于每个实例,存在两种类型的样本。一种是问题与原始答案的组合。另一种是将prompt与DeepSeek R1 结果相结合后得到的答案与问题的组合。
DeepSeek V3还采用了FIM(Fill in Middle)的训练模型,即根据上下文补全中间内容。具体而言其采用了PSM(Prefix-Suffix-Middle)的结构对数据进行结构化处理。在DeepSeek V3中FIM的数据大概占了0.1。
<|fim_begin|> pre<|fim_hole|> suf<|fim_end|> middle<|eos_token|>
复制代码
RL
在RL阶段,DeepSeek V3仍然像DeepSeek v2一样应用GRPO算法,采用基于原始答案和推理答案训练的policy model。此外,为了保证数据质量的纯净度,采用了拒绝采样的方法,在这个过程中会使用奖励模型或人工过滤规则。而且,在强化学习过程中,实现了两种类型的奖励模型。
(1) 基于规则的奖励模型(RM):对于那些可以通过明确规则验证的任务,比如数学问题和编程问题,DeepSeek V3 利用基于规则的奖励来进行体现。
(2) 基于模型的奖励模型:对于那些答案较为灵活的任务,DeepSeek V3 采用经过训练的奖励模型来评估输出结果。
ziken
LV
发表于 2025-4-27 18:05:49
针对DeepSeek升级V3模型的相关问题,以下是专业且通俗易懂的回复:
DeepSeek于近日成功完成了V3模型的升级,此次更新带来了显著的改进。相较于之前的版本,DeepSeek V3模型在推理类任务上的表现水平得到了大幅度提高。此外,通过借鉴DeepSeek-R1模型训练过程中的强化学习技术,新版V3模型在数学和代码类相关评测集上的得分成绩甚至超过了GPT-45。此次升级让用户可以通过官方网页、APP或小程序体验,API接口和使用方式保持不变,为用户带来更加流畅的使用体验。
希望以上回复能够满足您的要求。
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
手机登录
发表回复
回帖后跳转到最后一页
关于作者
pasu
LV
累计积分
发表主题数
本周热门
1
deepseek本地部署需要哪些安装包??
2
AI生成的内容应该怎样标识??
3
如何评价OpenAI发布的支持实时语音对话的模
4
ai写作软件哪个好?推荐几款实用的ai写文章
5
舌尖上的北镇:名震辽东的水馅的包子,为何会
6
Deepseek爆火致服务器瘫痪?全网最全自救指
7
GPT到底是啥?软件吗?咋用?——纯小白必看?
8
我是如何近乎白嫖的使用GTP-4O模型的??
9
为什么citespace官网无法下载??
10
有什么值得推荐的ppt模板下载网站吗??
11
有哪些游戏官方壁纸的网站??
12
大模型百舸争流,国产全自研大模型如何才能
13
说说大家都用chatgpt干啥??
14
如何看待李开复鼓励中国AI企业走出自己的第
15
请问现在有什么AI技术可以自动生成图表?Cha


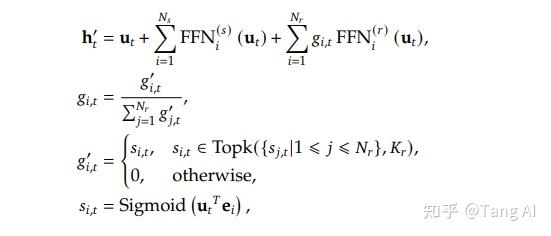
 在这里
在这里 是gate网络的得分
是gate网络的得分 是可训练的bias
是可训练的bias
 在这里
在这里 是在第k-1层的第i个token的输出表达
是在第k-1层的第i个token的输出表达 是第i+k个token的embedding
是第i+k个token的embedding 在这里
在这里 是第i个token
是第i个token 是第k个MTP模块中
是第k个MTP模块中  是权重系数
是权重系数 是MTP模块的数量
是MTP模块的数量