pxwwwd LV
发表于 2025-4-1 10:38:57
GR00T N1全称是通用人形机器人基础模型(Generalist Humanoid Robot Foundation Model),这个开源模型具备很强的任务泛化能力,可一套权重支持多种机器人形态(跨机体,cross-embodiment)和任务。例如,在无需为每个新任务从零训练的情况下,它已经掌握了常见操作技能:单臂或双臂抓取物体、搬运、装配,以及双手之间传递物品等。。它还能执行复杂的多步骤任务,理解长上下文指令,将一系列基本技能组合来完成人类日常活动中的高阶任务。
简单来说,你不用从头训练,它已经是一个具备基本能力的机器人,但如果你要让它做特定的工作,比如咖啡拉花,那你得在这个基础进行微调。
Github:GitHub - NVIDIA/Isaac-GR00T: NVIDIA Isaac GR00T N1 is the world's first open foundation model for generalized humanoid robot reasoning and skills.
HuggingFace:https://huggingface.co/nvidia/GR00T-N1-2B
首先恭喜宇树成为Nvidia的合作伙伴。
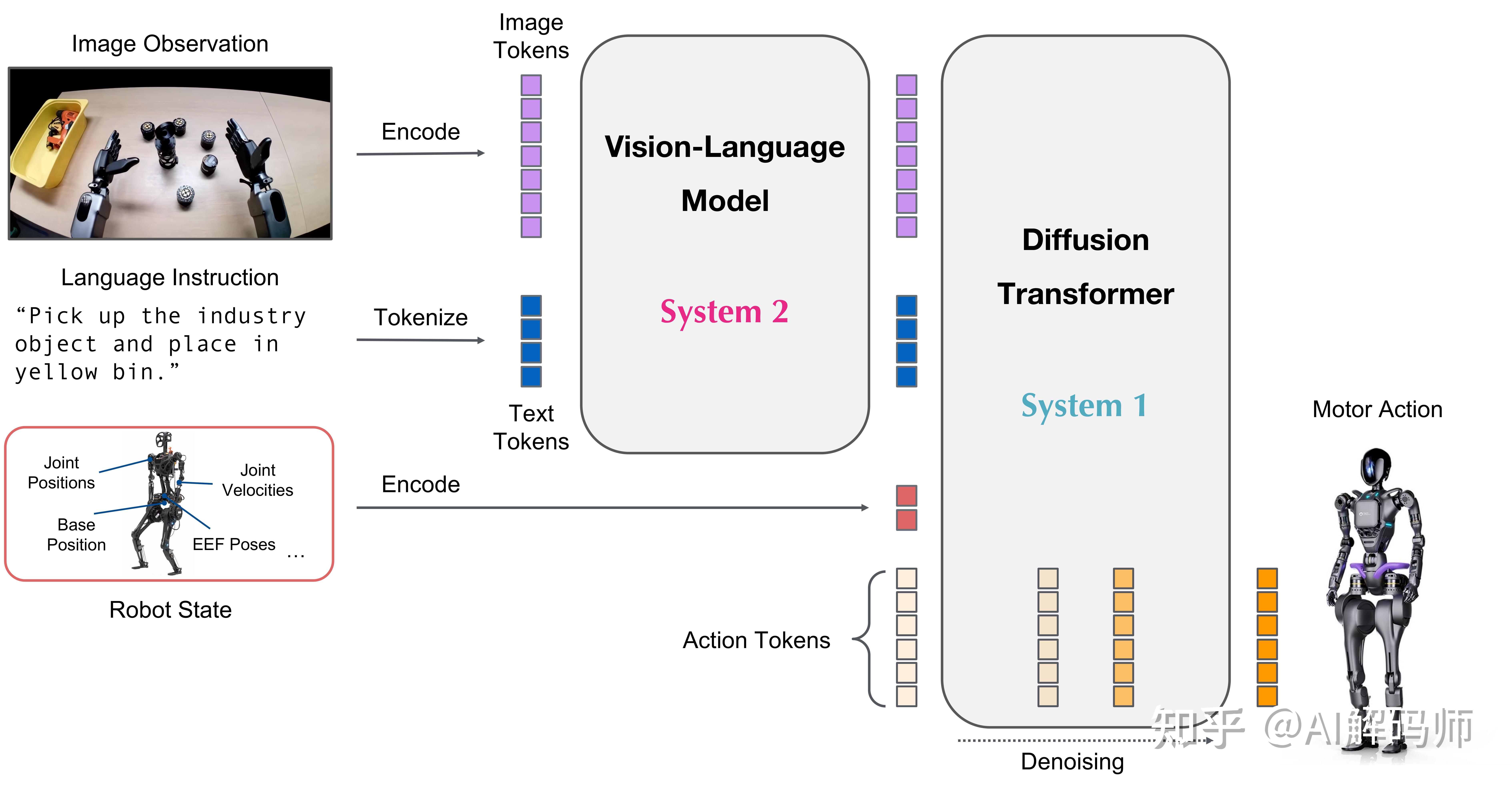
GR00T N1是一个双系统的机器人模型,你看它的流程图分为两个处理系统。
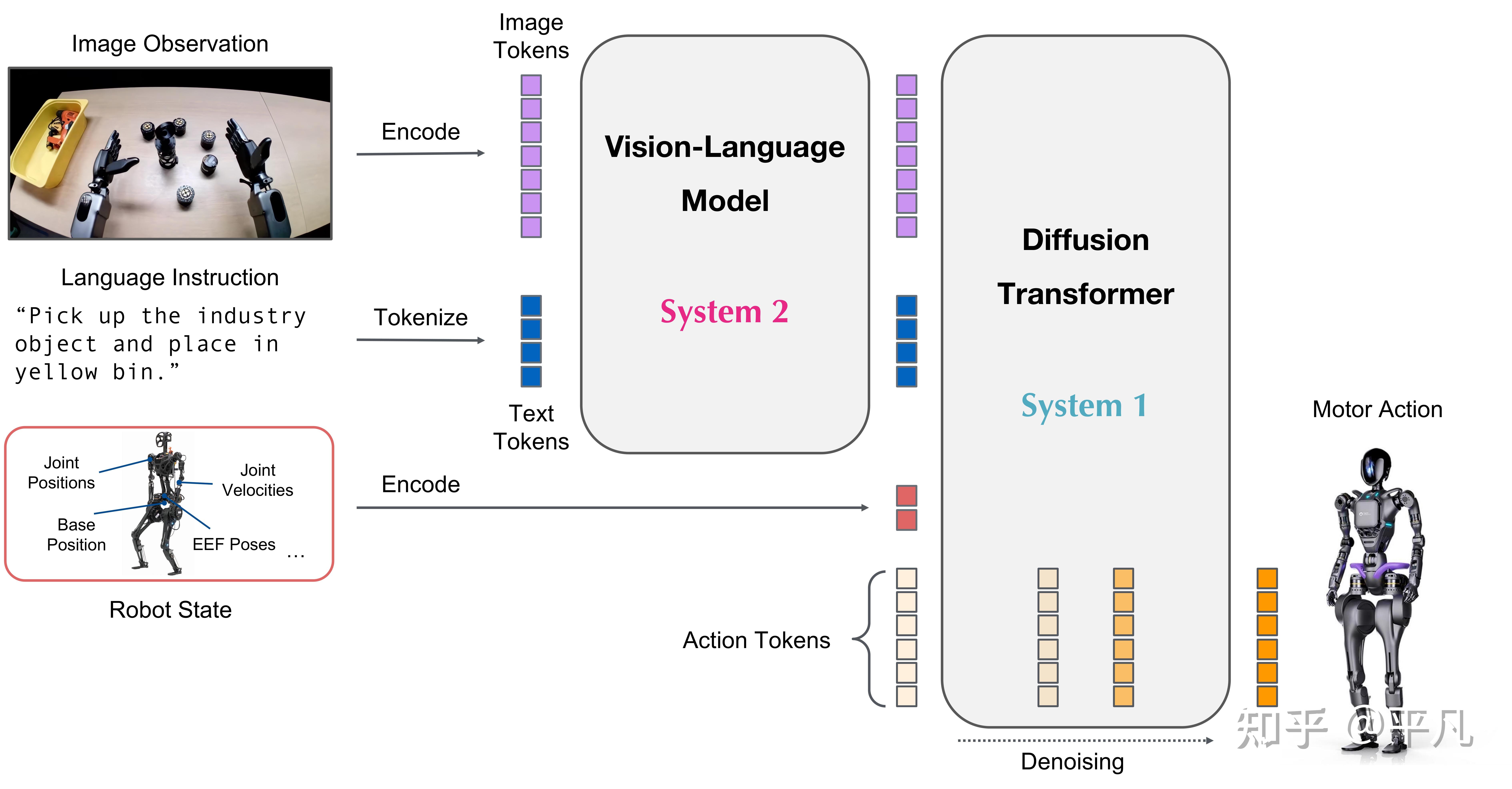
其中系统1是快速反应的动作控制模型,类似于人的直觉和反射,用于将高层指令实时翻译为机器人连续的运动控制;
系统2则是慢速推理的决策模型,内置视觉-语言Transformer模型,负责理解环境和指令并规划高层行动方案。
这种架构使GR00T N1能够一方面具备逻辑推理能力,另一方面确保动作控制的精细与及时。模型接受多模态输入(例如摄像头视觉、自然语言命令等),输出机器人操作序列,从而让机器人执行各类操纵任务。
这个框架跟sonnet-3.7很像,有快慢两种思考方式,对于不同的反应采取不同的分配比例。
数据来自两部分,真人数据和模拟环境数据,后者是由NVIDIA Omniverse和Cosmos共同完成的,跟自动驾驶的模拟数据来源如出一辙。
这个库的目标用户是:
- 利用预训练的基础模型进行机器人控制。
- 在小型自定义数据集上进行微调。
- 使用最少量的数据将模型适应特定的机器人任务。
- 部署模型进行推理。
使用流程:
- 用户需要收集机器人演示的数据集,格式为 (视频, 状态, 动作) 三元组。
- 将演示数据转换为 LeRobot 兼容的数据模式。
- 该仓库提供了配置不同机器人形态训练的示例。
- 该仓库提供了便捷的脚本来微调预训练的 GR00T N1 模型和运行推理。
- 用户将 Gr00tPolicy 连接到机器人控制器,以在其目标硬件上执行动作。
Here is the general procedure to use GR00T N1:
Assuming the user has already collected a dataset of robot demonstrations in the form of (video, state, action) triplets.
User will first convert the demonstration data into the LeRobot compatible data schema (more info in getting_started/LeRobot_compatible_data_schema.md), which is compatible with the upstream Huggingface LeRobot.
Our repo provides examples to configure different configurations for training with different robot embodiments.
Our repo provides convenient scripts to finetune the pre-trained GR00T N1 model on user's data, and run inference.
User will connect the Gr00tPolicy to the robot controller to execute actions on their target hardware. |
|